変数の宣言
学べる事
- 変数宣言の意味と仕組み
- メモリと変数の関係
.rodataセクションの役割と位置- アドレス
- セグメンテーション違反
- スタック領域
- スタック
- 再帰関数
- スタックオーバーフロー
前頁で確認しましたが、変数の宣言は以下のようなものでした。
int main() {
// データ型 識別子;
int x;
}
ですが、なぜ変数の宣言がこの文法で、データ型と識別子が必要なのかを考えたことはありますか?
今までのような、プログラムに宣言した変数やリテラルは、そのプログラムの実行中に、
メモリに展開されます。
ある変数を宣言するためには、あるメモリ上の性質によって変数のサイズを知っておく必要があります。
上記のコードでは、そのデータ型のサイズ分を x という識別子でメモリ領域と結びつける必要があるのです。
それらを確かめるためには、実際に見てみるのが早いですね!
Hello, World! の中身
前頁のHello, World!プログラムとobjdumpを使います。
その中で、文字列リテラル"Hello, World!"がメモリのどこに配置されるのか調べてみましょう。
$ objdump -s hello
ここで、objdumpに-sと一緒に渡しているhelloは、hello.cをコンパイルした実行可能ファイル(バイナリ)でしたね!
objdumpを使用することによって、実行ファイルを解析し、情報を整理してくれます。
さあ、ひたすらにHello, World!の文字列を出力から探してみましょう!
Contents of section .rodata:
2000 01000200 48656c6c 6f2c2057 6f726c64 ....Hello, World
2010 210a00 !..
# ↑ 仮想アドレスが 0x2000 の場所に "Hello, World" が配置されている
見つかりました!
どうやら、.rodata という部分に入っているみたいです。
勘の良い人は分かったかもしれませんが、.rodataとは、 Read-Only Data のことです。
すなわち、.rodataに置かれるデータは、すべて読み取り専用ということです。
このプログラムにおいて、printfの引数の文字列は変更する必要がありませんし、できません。
.rodata
次は、hello.cに以下の内容を足してみましょう!
#include <stdio.h>
int main() {
printf("Hello, World!\n");
// 文字列リテラルは通常 .rodata に配置される
char *msg = "Goodbye, my past self.\n"; // 追加
return 0;
}
今は、謎のアスタリスク(*)は無視してください。(これは、あの ポインタ です...)
ただ、整数リテラルがintになるように、 文字列リテラル はアスタリスクのついた* charになるようなものだと思っていてください。
これでもう一度、以下を実行します。
$ clang -o hello hello.c
$ objdump -s -j .rodata hello
上記のコマンドの、-j .rodata で.rodataのみを表示しています。
そして、表示が変わりましたね!
Contents of section .rodata:
2000 01000200 48656c6c 6f2c2057 6f726c64 ....Hello, World
2010 210a0047 6f6f6462 79652c20 6d792070 !..Goodbye, my p
2020 61737420 73656c66 2e0a00 ast self...
先ほどの表示の後に、新しく追加された文字列リテラルが.rodataに追加されましたね。
char *strlit = "文字列リテラル" のようなコードは、すべて読み取り専用データに対する アドレス(メモリの特定の位置) を得ています。
さらに、そのアドレスはその文字列の先頭(アドレス)を指しています。
ですので、このように変数として宣言しても書き換え不可能ということです。
#include <stdio.h>
int main() {
char* str = "文字列"; // .rodata に置かれている文字列のアドレスを得る
str[0] = 'a'; // read-only なデータに書き込もうとしてみる
return 0;
}
上記を実行すると、以下のようなエラーが出ます。
$ clang -o ref_rodata ref_rodata.c
$ ./ref_rodata
Segmentation fault (core dumped)
Segmentation fault(セグメンテーション違反) とは、アクセス権のないメモリにアクセスしようとしたことを意味します。
このプログラムで、読み込み専用なデータに書き込むことはできないことが実証できました!
なお、.dataセクションには書き換え可能な変数(グローバル変数)が置かれます。
ですが、* char(char* strlit)が読み取り専用データに対する位置を表す型ということではありません。
詳しくは、ポインタのページで解説します。
.rodata はどこに?
さて、次はその.rodataがメモリのどこに展開されるかを見てみましょう。
$ objdump -h hello
上記のコマンドを実行し、.rodataと書かれた部分を探してみてください。
Idx Name Size VMA LMA File off Algn
...
16 .rodata 0000002b 0000000000002000 0000000000002000 00002000 2**2
...
ありましたね!
VMA (Virtual Memory Address) の下に書かれている0000000000002000は、.rodata が
展開したいアドレス(仮想アドレス)を表します。
VMAは、OSが実際のメモリに対して、プログラム側で扱いやすいように(また安全のために)提供する仮想的なメモリのアドレスのことですが、詳しくは扱いません。
(仮想アドレス空間(英語) <- はこのページで話す内容と少し被っています)
また、厳密には実行されたときにロードされるアドレスとVMAが一致するとは限りません。
多くの場合、 ASLR, アドレス空間配置のランダム化の影響などを受けます
(ASLRを無効化すると、0x2000に.rodataが展開されます)
メモリ
メモリとして、以下のようなものを考えてみます。
.rodataはアドレスの0x0000000000002000に展開されましたね。
(注: 0xに続く数字は、16進数を表します)
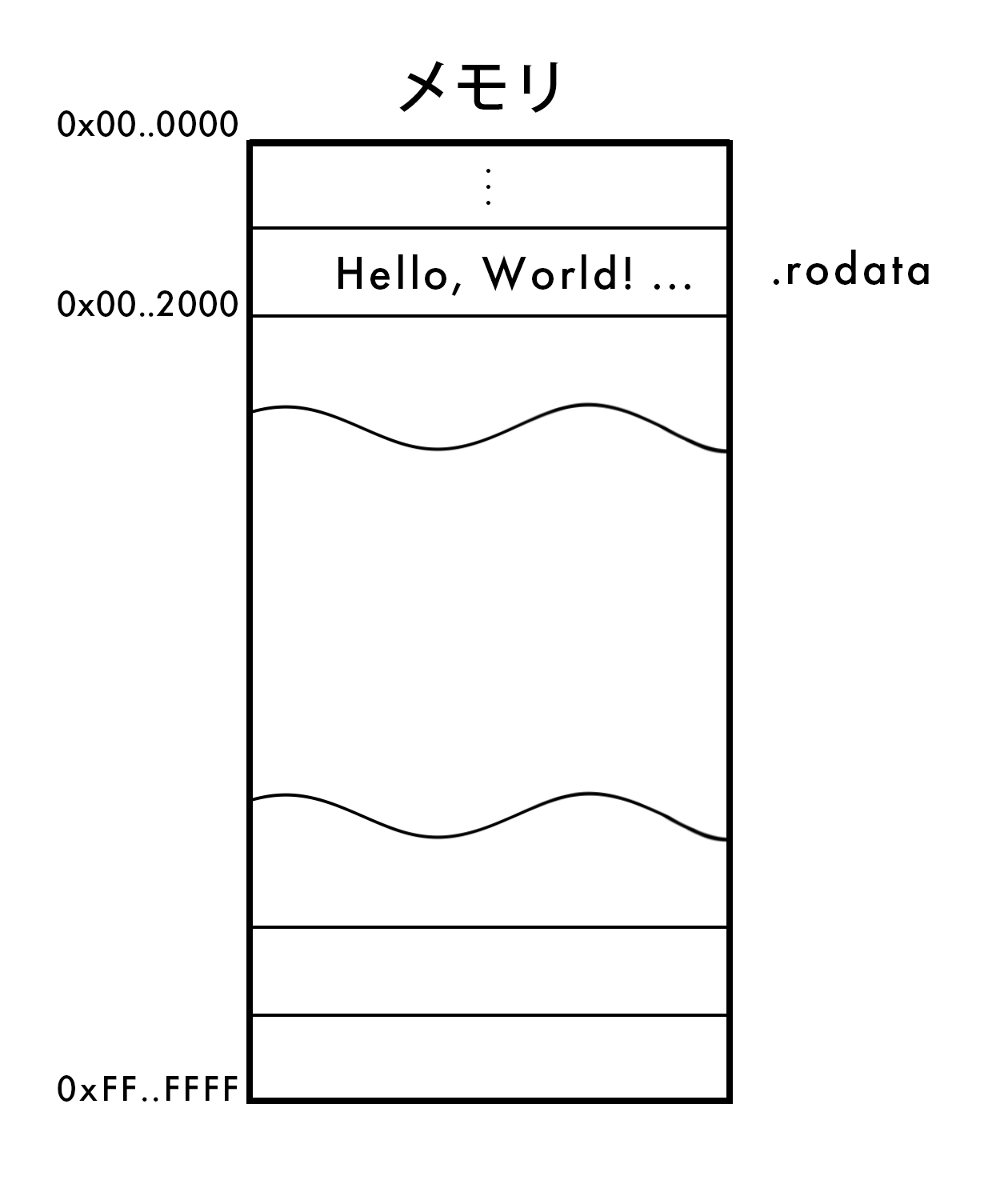
今までの情報から、以下のことが分かります。
- Hello, World!プログラムがコンパイルされたとき、
"Hello, World!"は読み取り専用の.rodataに配置される - このプログラムにおいて、文字列が書かれている
.rodataは、0x0000000000002000に展開される
実は、Hello, World!での文字列リテラルは、既に実行されたときに展開される場所が決まっているのです。
そして、この図で見るなら、かなり.rodataは上の方ですね!
また、これらはmain()などが実行される前に、メモリに展開されます。
今まで話した.rodataは、静的領域 と呼ばれるものの一部です。
これは、私たちの具体的な認識に対して抽象的な言葉ですが、メモリの一部として話されることがあります!
あれ? 私たちが宣言してきた変数はメモリ上のどこにあるのでしょうか?
スタック領域
今まで、コンパイルされた実行可能バイナリを解析して展開されるアドレスを見てきました。
今度は、プログラムで関数内に宣言された変数のアドレスを見てみましょう。
#include <stdio.h>
int main() {
int x = 0;
// %p で、アドレスを表示することができる
printf("%p\n", &x);
}
ここで、&xはその変数xが格納されているアドレスを得ることができます。
addr.c としてコンパイルし、実行してみます。
$ clang -o addr addr.c
$ ./addr
0x7ffd494ffecc
0x7ffd494ffecc という値が得られました。
これは、あなたの環境で似たような値が得られても、全く同じではないと思います。(先ほど注釈した、ASLRの影響です。何回か実行しても、値が変わると思います。)
さて、これらは今までのアドレスと異なって、かなり値が大きく見えますね。
実は、関数の中で宣言された変数は、 スタック領域 と呼ばれる、メモリの下の方に格納されます。
図に表してみましょう。
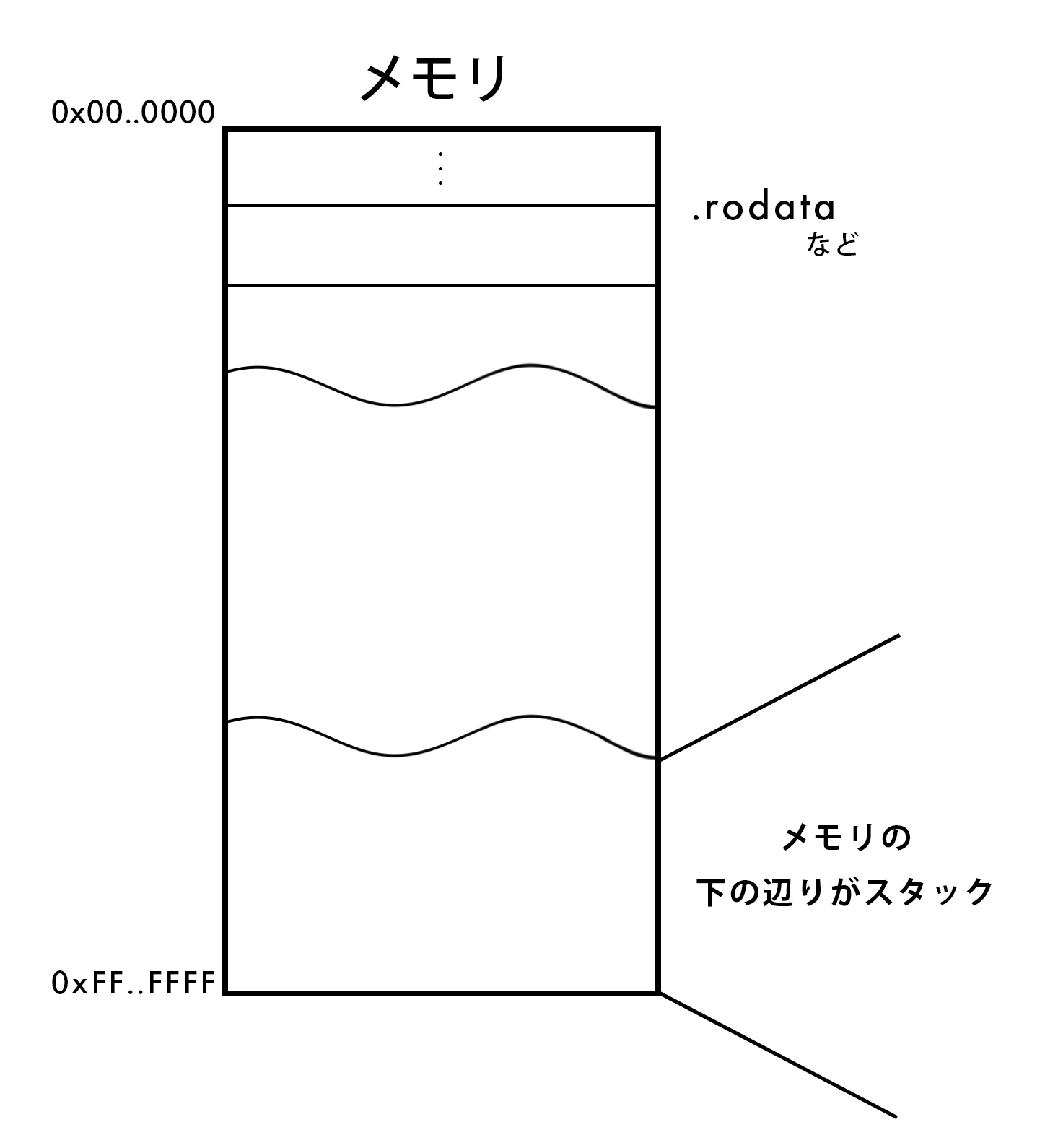
スタック領域は、多くの場合メモリアドレスの大きい方から、小さい方へ使われます。
より分かりやすくしてみましょう。
先ほどのaddr.cを以下のように書き換えてください。
#include <stdio.h>
int main() {
int x = 0; // 先にxを宣言
int y = 1; // 次にyを宣言
// それぞれのアドレスを表示
printf("x: %p\n", &x);
printf("y: %p\n", &y);
}
上記を実行します。
$ clang -o addr addr.c
$ ./addr
x: 0x7fff58c6dc8c
y: 0x7fff58c6dc88
xとyのアドレスを比べて、値の差をとってみると0x...c8c(cは10進数で12) - 0x...c88 = 4 でintのサイズと一致することも分かりますね!
また、変数yはxの後に宣言されたはずです。
ですが、xに比べて4バイト前のアドレスにあることが分かりますね。
これが、 スタック と呼ばれる所以です! (後でもっと詳しく説明します)
このプログラムを図に表しましょう。
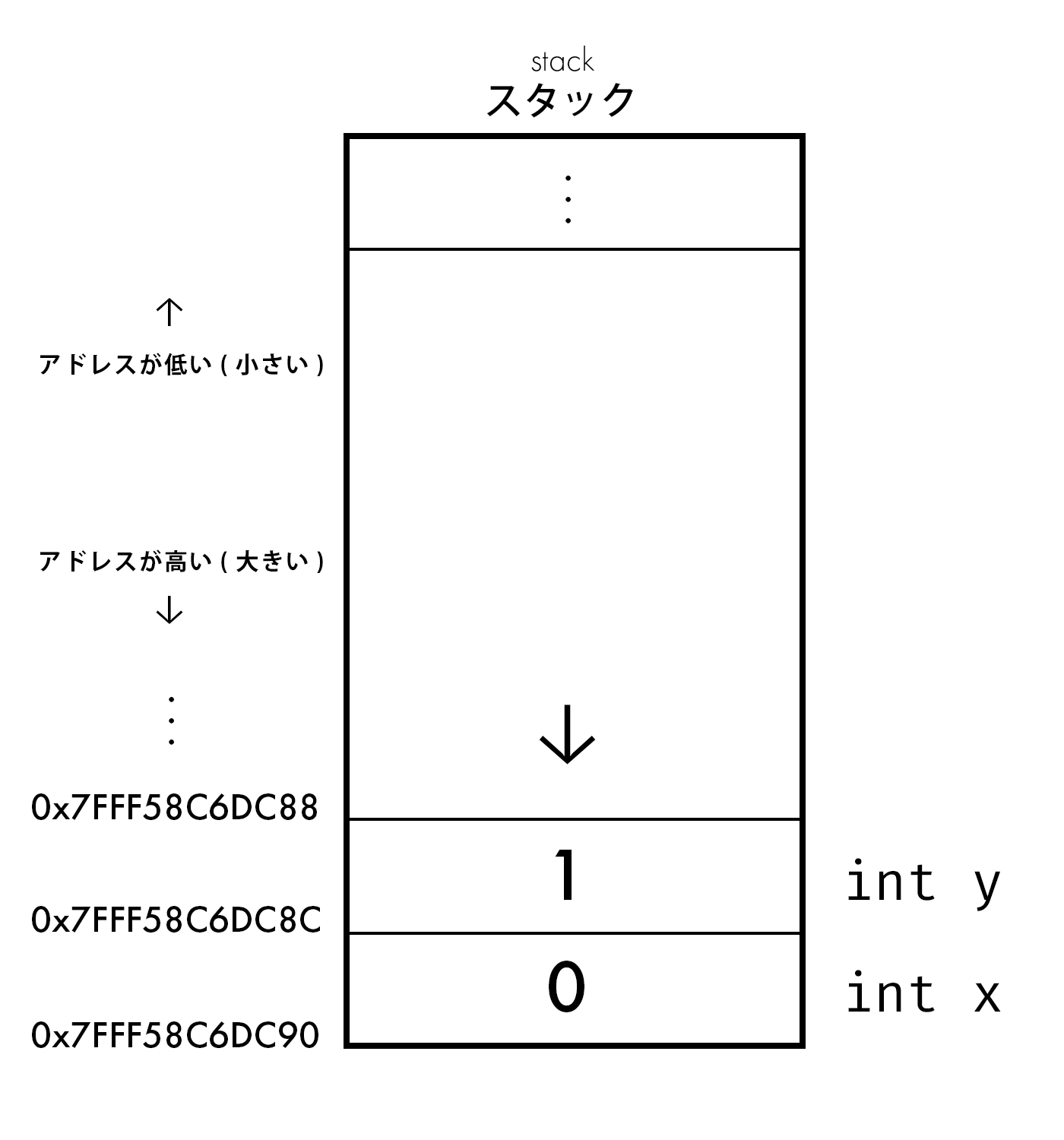
ここまでの内容を纏めます。
- 関数内に宣言された変数は、スタック領域に配置されます
- スタック領域の変数は、アドレスの大きい方から小さい方へと置かれていきます
スタック
スタック領域は、何がスタックなのでしょうか?
スタック領域は、変数を宣言し値を順番に入れていくと、また入れた順番とは逆の方向に値を取り除いていきます。
これを、 Last In, First Out (LIFO) といいます。
日本語で言うなら 「最後に入れたものが最初に出てくる」 というところでしょうか。
また、その LIFO の性質をもつのがスタックということです。
積み上げられている皿を想像して下さい。
皿を追加するときには、積みあがった皿の一番上に置き、皿が必要になったら、一番上から取り除きます。
また、積み上げられている真ん中の皿を取り去ったり、皿の一番下に追加することは出来ません。
スタック領域において、先ほどのプログラムでのxとyは積み上げられていますが、勝手にアドレスをずらしてその間に変数(値)が追加されることはないということです。
それにデータを追加することを、スタックにpushするといい、データを取り除くことは、スタックからpopするといいます。
今は気にしなくて大丈夫ですが、変数に結びつけられた値が積み上げられたあるプログラムのスタック領域があるとします。
それにおいて、すべてアドレスが連続的に変数と結びつけられた値が入っているというわけではありません。
これは、データ構造アライメント, メモリアライメント などと関係しています。
要するに、スタックだからといって、すべて変数と結びつけられた値が隙間なく詰め込まれているとは限らないということです!
Rustはどうして...?
Rustという言語は、変数の宣言に型が必ず必要ではありません。
う~ん、それはどうしてでしょうか?
以下のC言語のコードをRustで真似してみましょうか。
C言語:
// 省略
int x = 0;
//省略
Rust:
fn main() { // let 識別子 代入演算子 式; let x = 0; }
let は、データ型ではなく、変数の宣言のためのキーワードです。
今度は、C言語のこのコードを真似してみましょう。
C言語:
int x;
Rust:
fn main() { let x; // ...これでいいの? }
ご想像のとおり、このRustコードは以下のコンパイルエラーが出ます。
error[E0282]: type annotations needed
--> src/main.rs:2:5
|
2 | let x; // ...これでいいの?
| ^
|
エラー文には、"型注釈が必要です" と指摘されています。
ですので、以下のいずれかの方法で変数を宣言できます。
Rust:
#fn main() { let x: i32; // i32 であると指定 // 初期化しようが、変数xは i32 型(32bit整数)の変数 let x; // 0 が代入されているので、xは自動的に i32 と判断される x = 0; #}
Rustは、型推論という仕組みを利用して、変数に適切な型を自動的に割り当てます。たとえば、以下のコードを見てください。
fn main() { let x = 42; // 型推論によって x は i32 と判定される let y: f64 = 3.14; // 明示的に型を指定することもできる }
型が判明することによって、どんな値かが分かれば、そのサイズも分かりますね。
このことから導き出される結論は以下の通りです。
スタックに変数を宣言するためには、どんな言語であれ サイズ を知る必要があります。
C言語の以下のコードにおいて、なぜ変数の宣言ができるかというと、サイズが分かるからです。
int x;
intは基本的に4バイトでしたね。
なので、スタック領域に4バイト分を使うということを宣言しています。
(変数の宣言をした時点で、基本的にはスタックに置かれるアドレスが決定されます。決して、アドレスは代入時に決定されません)
Rustでも、このようにすれば サイズ を知ることができます。
fn main() { let x: i32; // 32bit の分スタックをxが使うことを宣言する }
変数の宣言がおおよそ何をしているかが分かりましたか?
なぜサイズが判明しないといけないか
最初に、C言語において、宣言する変数はサイズが判明していないといけないと言いました。
スタック領域に変数を積み上げるとき、サイズが分からないとどうしようもありません。
例えば、スタック領域に配置される、あえてサイズが不定の変数xを宣言できるとしてみましょう。
加えて、int型の変数yを宣言するとき、一つ下の変数xのサイズが分からないのに、どこに積み上げれば良いのでしょうか?
逆にその上の4バイト上のアドレスをyがとるものと仮定しても、xが4バイトを超えるデータを書き込んだ場合、yの領域を突き抜けてしまいますね!
そういった意味で、スタックにどのような変数や値が積まれるかは、コンパイル時にある程度判明していなければならないということです。
ここで、賢い人なら疑問に思ったかもしれません。
もし、プログラム内でどのような変数がスタック領域に配置されるかが判明するなら、コンパイラは予言的で、すべてのスタック領域の変数の動きも既に決まっているのでしょうか?
また、スタックのすべての動きを追うことができるなら、再帰的に自身の関数を呼ぶようなものはどのようにコンパイルされるのでしょうか?
実は、コンパイル時にサイズが決まっている変数は、関数(ルーチン)毎にサイズが計算されます。
関数内で宣言される変数や、関数の呼び出し元はどこか、引数は何かなど、様々な情報を纏めて、関数ごとにサイズが計算されています。
この様々な情報の集合を、 スタックフレーム といいます。
再帰関数
先ほどの"再帰的に自身の関数を呼ぶようなもの"の例をみてみましょうか。
#include <stdio.h>
int func(int x) {
printf("%d\n", x);
int y = 1;
return func(x + y);
}
int main() {
func(0);
return 0;
}
このコードにおいて、func() は、再帰的であるといえます。
func()は、main()から最初に受け取った0に、yの1を足していき、また自身を呼び出すために渡される値xは増加していきますね。
このコードをrec.cとして、実行してみます。
$ clang -o rec rec.c
$ ./rec
0
1
2
3
...
261877
261878
261879
Segmentation fault (core dumped)
Segmentation fault を起こしてしまいました。
これは不正なメモリアクセスに対して発生するものでしたね。
また、コンパイラは、プログラムのすべての流れを追うように変数のサイズを計算するのではなく、関数ごとに行われているといいました。
func()はint型の引数xと変数yを宣言しており、main()に呼ばれた、またはfunc()自身から呼ばれたなどの情報の集合が、スタックに配置されることがコンパイル時に判明しています。
ですので、予言的にスタックにどんな値が積まれるかを知ることはしていませんが、関数ごとに使用するスタックのサイズや、どのように積むかはコンパイル時に分かっているということです。
ここでは、func()のスタックフレームが、コンパイル時に判明しています。
関数呼び出しが無限に行われることによって、スタックに情報が積み上げられ続け、スタックの容量の限界を迎え、別のメモリ領域を突き抜けようとしたために、Segmentation fault が発生したということです。
これを、 スタックオーバーフロー (Stack overflow) といいます。
(また、実行するたびに表示されるxの値が変わると思いますが、それもまたASLRの影響です... 簡単に言うと、スタックの開始アドレスがランダムに変わるためです)
では、サイズがコンパイル時に判明している変数やデータしか、プログラムで扱うことができないのでしょうか?
ここで、メモリ上のアドレスを0x000..000から0xFFF..FFFのどれかを保持するために、サイズが判明している変数pを考えてみましょう。
また、値を積み上げず、レストランのように空いている場所に値を書き込んでいく別のメモリ領域を考えてみましょう。
これを、ヒープ領域 としてみます。
pは、サイズが判明するために、スタックに配置されます。
pが保持するアドレスをヒープ領域を指すものとすることによって、この時点でコンパイル時にpのサイズは判明するものの、そのアドレスが指す値のサイズは実行前に分からない、ヒープ領域上でサイズ変更が可能なデータを扱えるようになりました。
そうです。私があえて話していなかった、メモリ図の真ん中辺りの領域は、ヒープ領域だったのです。
詳しくは、ポインタを解説した後にしましょう。
ですがポインタは、アドレスを保持し、それが.rodataやスタックやヒープ領域を指すことができるというのです。
(ここで、あえてこの変数pをポインタであると言わなかったのは、ポインタとは単純なアドレスを保持するものではないからです。
混乱させるようですが、中級者の方はStrict Aliasing Rulesなどを調べると、自身での新たなポインタの解釈が生まれてくると思います。
ここで、それらを加味した、現時点での私の解釈を言うのであれば、『ポインタとは、ある記憶域から生成されたオブジェクトを一意に決定できる値とそのオフセット』です。ですが、分からない人は全く気にしないで下さい。)
次は、今まであえて使っていなかった、制御構造(e.g. if, while)や、文と式について話します。