Programming Reboot Book
はじめに
Programming Reboot Bookは、プログラミングの基礎を一から学び直したい人のための入門書です。
本書の目的
本書の目的は、プログラミングの基本的な概念を C言語、Java、Python、Rust の4つの言語を通して私の観点から説明していきます。また、プログラミングに挫折した経験がある人に向けて、おすすめできるような本にしていきたいです。
本書の特徴
- プログラミング言語は、C言語、Java、Python、Rustの4つの言語を使って、プログラミングの根幹を解説しています
- 変数、データ型、制御構文、などといった基礎概念がなにをしているのかを丁寧に解説していくつもりです
- 特に説明するために、あえてアバウトな表現を使ったり、言及する内容を絞ることがありますが、より深く調べたい人のために、できるだけ注釈しています
本書の対象読者
- プログラミングの経験はあるが曖昧でよく理解できていない人
- 過去にプログラミングに挫折した経験があり、もう一度基礎から学びたい人
C言語
この本にC言語 が採用されていることを疑問に思う人もいるかもしれません。
ですが、C言語の開発者であるデニス・リッチー の言葉に以下のようなものがあります。
この本を読んでいるあなたの目的は分かりませんが、もしあなたがC言語を学ばざるを得ない状況で、背景を知らず使っていたとしたら、歴史を知ることはいい機会かもしれません。
ここは読み飛ばして頂いても結構ですが、C言語の情報を少し見てみましょう。
C言語の歴史
C言語は、1972年にAT&Tベル研究所 のデニス・リッチーが主体となって開発したプログラミング言語です。
Unix (Linux などの前身)というOSを作るために開発されたと思われがちですが、実際のところC言語は、Unixを開発するために作られたB言語 を改良するために生み出された言語なのです。
B言語の開発者であるケン・トンプソン は、同僚のデニス・リッチーに協力を求め、B言語の欠点を改善した新しい言語の開発に取り組みました。その結果が、私たちが今日知るC言語なのです。
こうしてC言語は、Unixの開発という具体的な課題に応えるために誕生したのです。
以降、C言語は高い信頼性と効率性から、オペレーティングシステムやシステムプログラミングの分野で広く採用されるようになりました。
この歴史を振り返ることで、C言語がなぜ開発され、どのような特徴を持つ言語なのかが理解できるでしょう。
次のページでは、実際にC言語の環境構築の方法や文法、基本的な使い方を見ていきましょう。
Hello, World!
この本は途中まで、または一通りC言語を学んだことを前提としています。
何もプログラミングについて知らないという方は、入門者向けの文書を読むと嬉しいことが多いと思います。
環境構築
C言語のソースコードの実行環境を作っていきましょう。
もう既にできている人は飛ばしてください。
ここでは、Windows×VSCodeの例を示します。
Windowsでは、おそらくWSL上にC言語の環境を作るのが最も簡単で便利でしょう。
WSLを使いたくないという人は、別の方法を参照してください。
(ですが、解説の途中でobjdumpのようなWindows(非WSL)で使えないツールを用いて説明することがあります)
WSLで環境構築
-
PowerShellを管理者権限で起動
PowerShellを管理者権限で起動(
Win+X->A)し、コンソール内で以下を実行します。wsl --install
これで自動的にUbuntuがインストールされます。
-
Ubuntuの起動
WSLのインストールが完了したら、次のコマンドでUbuntuを起動します。ubuntu
-
パッケージのアップデートとClangのインストール
初期設定が完了したら、以下を実行してシステムを最新状態にし、Clangをインストールします。sudo apt update && sudo apt upgrade sudo apt install clang
-
VSCodeのセットアップ
WSLを閉じ、VSCodeを起動します。次に以下の拡張機能をインストールしてください。WSLC/C++ Extension Pack
左下の
「リモートウィンドウを開きます」->「WSL への接続」でVSCodeからWSLへ接続してください。
別の方法
-
コンパイラのダウンロード
このリンクから、あなたの使っているCPUのアーキテクチャ(注)と同じものをダウンロードしてください。(
注: Windows11だと、設定のシステム > バージョン情報のシステムの種類からCPUのアーキテクチャの種類を確認できます)
最近の大抵のWindowsマシンはx86-64なので、このページから、llvm-mingw-yyyymmdd-ucrt-x86_64.zip をダウンロードしてください。
-
ファイルの解凍・配置
ダウンロードが終わったら、圧縮ファイルを解凍し、任意のフォルダ(e.g.C:\llvm-mingw)に移動させてください。
-
環境変数の設定
次に、エクスプローラー上で、そのフォルダの中にあるbinフォルダを含めたパスを環境変数に追加してください。(e.g.C:\llvm-mingw\bin)(
注: 分からない場合は調べてみてください。色んなサイトを漁ってみることも時には重要ですよ!)
-
確認
コマンドプロンプト上で、以下を実行後、clangが起動されることを確認してください。clang
- VSCodeのセットアップ
VSCodeを開いて、拡張機能のC/C++ Extension Packをインストールしてください。
コンパイル
VSCodeのエクスプローラーから、C言語のソースコードを置きたいフォルダを開きます。
新しいファイルhello.cを作成し、以下の内容を入力してください。
#include <stdio.h>
int main() {
// "Hello, World!"を改行付きで表示
printf("Hello, World!\n");
return 0;
}
VSCodeのターミナルを開き、以下を実行してHello, World!と表示されたら成功です。
clang ./hello.c -o hello.exe
次は、本格的にあなたが少し知っているC言語が、「いったい何をしているのか」 というところを学んでいきましょう。
基本事項
次のページから、C言語の解説に入りますが、このページで言及されることを知っている前提で、話を進めていきます。
さっと読んで、よく知らない内容があった場合は読んでおくことをおすすめします。
学べる事
学ぶこと-前半:
graph TD
A[プログラム実行] --> B[関数]
B --> C[変数]
B --> D[main関数]
C --> E[データ型]
C --> F[初期化]
E --> G[整数型]
E --> H[浮動小数点型]
E --> I[文字型]
D --> J[引数]
D --> K[返り値]
後半:
graph TD
L[プリプロセッサ] --> M[#include]
M --> N[標準ライブラリ]
N --> O["stdio.h"]
O --> P[printf]
O --> Q[scanf]
O --> R[fgets]
O --> S[putchar]
O --> T[getchar]
データ型
C言語には、データ型(型)というものが存在しています。
主に、ある値(データ)がどのような種類か、またそのサイズなどを知るために使用されています。
例えば、132なら整数。10.2なら小数。'a'なら文字のようなものだと分かります。
すべてを挙げることはできませんが、以下は主なデータ型の例です。
(サイズはプラットフォームによって異なることがあります)
| データ型 | 種類 | サイズ | 範囲 |
|---|---|---|---|
| int | 整数 | 32bit | -2,147,483,648 ~ 2,147,483,647 (-2^31 ~ 2^31-1) |
| unsigned int | 整数 | 32bit | 0 ~ 4,294,967,295 (0 ~ 2^32-1) |
| short | 整数 | 16bit | -32,768 ~ 32,767 (-2^15 ~ 2^15-1) |
| unsigned short | 整数 | 16bit | 0 ~ 65535 (0 ~ 2^16-1) |
| long long int | 整数 | 64bit | -2^63 ~ 2^63-1 |
| char | 文字 | 8bit | -128 ~ 127(多くの場合) |
| float | 浮動小数点数 | 32bit | 3.4E +/- 38 (7 桁) |
| double | 浮動小数点数 | 64bit | 1.7E +/- 308 (15 桁) |
これらを暗記する必要はありません!
正確には、暗記しなくてもどのような値をもつデータ型かを理解できるほどコードに慣れて貰えると嬉しいです。
上の表には普段あまり使わないものもあるので、違いを理解してそのようなデータ型が存在することを認識してもらうだけで結構です。
リテラル
C言語のプログラム内に値を直書きしたとき、これらは リテラル と呼ばれます。
プログラム中に、例えば100と書いたとき、これは 整数リテラル で、基本的にint型になります。
また、12.3と書いたとき、これは 浮動小数点リテラル で自動的にdouble型になります。
いろいろ書きましたが、結局は「データの種類を表すのがデータ型である」と理解してもらえれば結構です。
ただ、コンパイラはプログラム中に直書きされた57という数字を見つけたとき、
「int型で4バイト(注1 32bit)の整数があるじゃん」
と認識するということですね。
なぜ、プログラム中に直書きした12.3がよりサイズの小さいfloatではなくdoubleになるのでしょうか?
現代のCPUでは、floatもdoubleも計算の速度はほぼ同じです。
普通のプログラムでは明示しない限り、より精度の高い小数を扱えるならdoubleの方が良いと考えられています。
これは、Rustという言語でも同じで、浮動小数点リテラルはf32(32bitの浮動小数点数)ではなくf64(64bitの浮動小数点数)になります。
あえて、floatを使う例を挙げるなら、特に一つの変数に細かい精度が重要でない、大量に変数が必要となるシミュレーションや機械学習などのプログラムは32bit以下の精度の浮動小数点数が使われていることが多いです!
補足ですが、floatのリテラルを使いたければ、12.3fと書くことができます。
変数の宣言
C言語では、変数 というものがあります。
int main() {
// データ型 識別子;
int x;
}
このCコードで、xは変数です。
また、これは変数xを 宣言 しています。
あえて、「変数は箱である~」のような陳腐な表現を避けて説明します。
詳しくは今後話しますが、あなたがこれを読んでいるコンピューターにはメモリ(主記憶装置, RAM)というものが積まれていますね。
変数の宣言がされると、データが配置できる特定のメモリの場所から、データ型から分かるサイズの量(この例では、intで4バイト)、この変数名xと結びつけて使うよ、ということになります。
ですので、この変数xを通してint型の4バイト分を使用することができるということですね!
(実際には、使われていない無駄な変数が宣言されないようになったり、より高速化するためにCPUの記憶装置(レジスタ)のみにデータが配置されることがあります)
ですが、メモリのある場所を使うということを宣言しただけです。
本当に、この変数の中身が何が入っているか分からないのです。
これは不定の値なので、プログラムでは基本的に危険です。
以下のように安全な値にしてあげたいですね!
int main() {
// データ型 識別子;
int x;
// 識別子 代入演算子 式;
x = 0;
}
代入
変数に値を入れることを、代入 といいます。
それらは代入演算子=を用いて行われます。
x = 0だと、xに0を代入(書き込み)するということになります。
また、この中身の分からない変数xのような、不定な変数 の中身に値を代入し、どのような値か分かるようにすることを初期化 といいます。
識別子
補足すると、上記コードのコメントに書かれている 識別子(Identifier) は変数名と読み替えてもらってもこの例では構いません。
これは、ユーザーがC言語のキーワード(e.g. if, while, return, ...)に被らない範囲で、自由に定義できる名前のようなものです。
コンパイラがプログラムの文脈の中で、特定の識別子が他のものと同じであることを、判別するために 識別子 という名前になっています。
ここでは、宣言したxと、0という値が代入されているxが同じものであると識別されるということです。
私たちが書くのは、ただの文字列に過ぎませんが、コンパイラはそれを意味づけるのです。
ですので、代入においては、コンパイラがある変数の識別子を知っていればその情報を元に処理をしますし、知らなければ宣言されていない変数としてエラーを出すということです。
また、先ほどのコードは以下のように書くことができます。
int main() {
// データ型 識別子 代入演算子 式;
int x = 0;
}
少し纏まりましたね!
実は、識別子は多くのプログラミング言語で、数字から始めることができません。
(もちろん、C言語もその仲間です。)
もしもあなたがプログラミング言語が好きで仕方が無く、向上心があるのであれば、コンパイラ(言語処理系)の実装をしてみると良いかもしれません。
なぜ、多くの言語で識別子が数字から始めることができないのかが分かるはずです。
ネタバレ: 面倒だから (多くの場合)
関数
C言語において、 関数 はコンピューターが実行する命令や、手続き(プロシージャ)が書かれたルーチンを表します。
すなわち、「特定の処理をひとまとめにして名前をつけたもの」と言うことができます。よく「料理のレシピ」に例えられます。例えば、「カレーを作る」というレシピがあれば、その手順に従うことで誰でもカレーを作ることができますね。
関数も同じように、「これこれをしたら、こうなる」という処理の手順(手続き)が書かれていて、その手順に名前が付けられています。関数を使うことで、同じ処理を何度も書く必要がなくなり、プログラムがすっきりして読みやすくなります。
(すべて関数が、読みやすくするために、また何度も書かないでよくするために存在するという訳ではありません)
main関数
関数はmain関数とそれ以外のものに分けることもできます。
main関数は、mainという名前が付けられた以下のような特別な関数です。
int main() {
return 0;
}
ここで、main関数はプログラムの最初に実行される(注2)、エントリポイント で、プログラムの中心となる メインルーチン になります。
ですので、main()でない関数はすべて、メインルーチンから呼び出されるサブルーチン になるということです。
特に、そのサブルーチンは、プログラマーが定義する ユーザー定義関数 と、C言語に元から用意されている関数を (標準)ライブラリ関数 といいます。
ユーザー定義関数のコード例は以下のようなものです。
// データ型 識別子(データ型 変数名, …)
int add_one(int a) {
return a + 1;
}
これは add_one という名前の関数です。この関数は、int 型の数を受け取って、それに 1 を足した結果を返します。
関数の構成要素
関数名: add_one のように、関数の名前です。
引数: 関数に渡す値です。add_one 関数では int a が引数で、呼び出し元からの整数を受け取ります。
戻り値: 関数が返す値です。add_one 関数では、a + 1 の計算結果が戻り値です。
データ型: int add_one(int a) の最初の int は、この関数が返す値のデータ型(この場合は整数)を表します。
関数名
関数において、関数名も識別子です。
呼び出したい関数と実際に定義されている関数はもちろん同じものでないといけないですね。
コンパイラは、呼ばれている関数が本当に定義されていて、どのようなものかを特定したいのです。
もちろん識別子なので、先ほどの変数の識別子のように、数字から始めることはできませんし、キーワードと被ってはいけないということです。
引数
// データ型 識別子(データ型 変数名, …)
int sum(int x, int y) {
return x + y;
}
上記は関数の宣言で、最初のintと書かれたデータ型は、この関数が返す値のデータ型を表しています。
また、()内に書かれた(int x, int y)は引数(仮引数)というものです。
このコードでは、仮引数としてint型の変数xとyを 仮に定義 しています。
これは、intの変数として、別の関数から呼び出されることを仮定して 記述しています。
ですので、このsum()を呼び出すときには、必ずint型の値を二つ入れる必要があります。
まとめると、sum()は、intの変数を二つとり、その変数の値を合計してintを返す関数ということです。
関数呼び出し
先ほどのコードを 関数呼び出し してみましょう。
int sum(int x, int y) {
return x + y;
}
int main() {
int result = sum(1, 2); // 3
printf("%d\n", result); // 表示!
return 0;
}
このコードで、sum()は1と2を受け取ります。
sum()内で仮に定義された、xとyとが足されて呼び出し元に返却されるという処理が、引数として渡された1と2に適用されるので、3と評価されます。
もちろん、私たちが最初に実行した、Hello, World!プログラムで使用したprintf()も関数であり、関数呼び出しをしているということです。
後で詳しく見ていきますが、printf()内では文字列が最初の引数にくることを仮定して定義されているため、呼び出す際には"Hello, World!" などと()に文字列を入れる必要があるということです。
(正確には、printf()は引数にフォーマットしたい文字列と可変長引数が仮に定義されている)
注意!
int add_one(int a) { // 呼び出し元の x と同じ変数名にする必要はない
return a + 1;
}
int main() {
int x = 0;
int y;
// 0 + 1 の結果がyに代入される
y = add_one(x); // add_one() を使うためには、intの値を入れる必要がある (e.g. x, 0, 123)
printf("%d", y); //Output: 1
return 0;
}
上記コードでは、xを0で初期化し、宣言したyに値を代入しています。
また、add_one()は先ほど定義したものを呼び出しています。
呼び出し元では、add_one()の関数定義で宣言した仮引数aと同じ名前にする必要はありません。
なぜなら、ある関数の宣言された引数や変数の識別子は、その関数内でしか使うことができませんし、他の関数の識別子が、宣言したものと勝手に衝突するようなことは、あってほしくないですね。
ですが、add_one()はint型の変数を使って1を足すという処理をしているので、呼び出し元で同じint型の変数を引数として呼び出さ なければならない ということです。
別の例を見てみましょう!
返り値
// データ型 識別子 (引数)
double multiple(double left, double right) {
return left * right; // 掛け算して返す
}
この関数の宣言で、return ~; は~の部分に、呼ばれた元の関数にどのような値を戻すか を記述します。
これを、返り値(戻り値) と言います。
先ほど言いましたが、この関数の宣言で、頭に書かれるデータ型(double)は、この関数が返すデータ型を表しています。
つまり、return で返す返り値と、関数の宣言で返すと書いたデータ型は一致させなければなりません。
もし、関数の宣言でintを返すと書いているのに、関数の宣言で浮動小数点数(小数)を返そうとしていたらびっくりですね!
// ↓int型を返す関数であると宣言
int return_int() {
return 1.1; // double型...? (呼び出し元は、int型が返ってくると思っている)
}
ですので、呼び出す側も、返す側も同様にデータ型は一致させる必要があります。
このコードはコンパイラによって、警告が出ると思います。
これは、大きな文法上の問題は無いが、問題のあるコードの記述に対して行われるものです。
最近のコンパイラは親切なことが多いので、エラーや警告のメッセージを読んで理解するようにしましょう!
補足
補足ですが、returnが実行された時点でその関数は終了し、呼び出し元に処理が戻されます。(main関数でも同様)
int routine() {
return 0;
//--- main関数であっても、ここから下のコードは実行されない
printf("表示して!"); // ※表示されない
return 123; // return の数に制限はありません(このコードでは実行されませんが)
}
このコードでは、returnの下に処理が書かれています。
returnが実行されていなければ、表示して!と標準出力されるはずですね。
ですが、条件分岐していようとなんだろうと、結局はreturnが実行された時点でその関数は終了します。
(void)って何?
main()の定義にint main(void) {と書いてあるプログラムを今後見るかもしれません。
(void) は関数の引数が何もないことを表します。
まず、C言語の古い言語仕様(C90など)には、引数がない場合、voidを書くことが推奨されていました。
最近のCコンパイラもvoidがなくてもコンパイルエラーにはなりません。
かなり古いコンパイラを使うという場合でなければ、今ではお好みということです。
課題 1
int型の仮引数を1つ宣言し、それを二倍して、呼び出し元に返却するdouble_int()を実装してください。
Hello, World! 2
最初のHello, World!のコードに戻ってみましょう!
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
ここで、main()はintの0を返却するメインルーチンです。
0を返却する理由は、プログラムが正常に終了したことを示す標準的な方法とされているからです。
これは、OSがこのプログラムを実行したとき、main関数の戻り値をプログラムの終了コードとして利用することに由来します。
多くのOSでは、0を返すと「正常終了」を意味し、0以外の値は「異常終了」を示すことが多いです。
ちょっとしたお約束のようなものですね!
プログラムの最初には、printf()を用いて"Hello, World!"を 標準出力 しています。
これについては、少し後で説明します。
基本的には、実行したプログラム(e.g. Windowsならコマンドプロンプトなど)に内容が引き継がれ、それに表示してもらうことになっています。
ですので、この場合では"Hello, World!"が表示されますね!
プリプロセッサ指令
#includeについて説明していませんでした。
このような#から始まる記述を、 プリプロセッサ指令 といいます。
#includeは、主に、関数の宣言、マクロ、構造体定義、定数などを他のソースファイルから取り込むために使われます。
すなわち、他のプログラムで宣言された内容を、自分のプログラムで使用できる(呼び出せる)ということです。
なぜ、これが必要かというと、printf() は #include <~> をしている、stdio.h に含まれているからということですね。
標準ライブラリ
#include <stdio.h> は、C言語の規格に合わせて実装された、便利な関数が纏めて実装されている、
標準ライブラリ の"stdio.h"を使用しています。
stdio.hの"std"は、Standard(標準)の略で、"io"は Input/Output(入出力) を表しています。
ですので、これをインクルードする(含める)ことで、標準ライブラリの入出力関数を扱うことができます。
いつか詳しく話すかもしれませんが、I/O(Input/Output) はコンピューターの仕事で、プログラムからはそれにお願いをしなければなりません。
実行しているプログラムからOSに行うお願いを、System call(システムコール) などと言います。
では、あえてstdio.hを使わずにHello, World!してみましょう。
void main() {
// 出力する文字列
const char message[] = "Hello, World!\n";
const long message_length = sizeof(message) - 1;
// writeシステムコールを呼び出す
asm volatile (
"mov $1, %%rax\n" // write のシステムコール番号 (1)
"mov $1, %%rdi\n" // 標準出力 (ファイルディスクリプタ 1)
"mov %0, %%rsi\n" // 書き込む文字列のアドレス
"mov %1, %%rdx\n" // 書き込む文字列の長さ
"syscall\n" // システムコールを呼び出す
:
: "r"(message), "r"(message_length) // 入力オペランド
: "%rax", "%rdi", "%rsi", "%rdx" // 破壊されるレジスタ
);
// exit システムコールを呼び出す
asm volatile (
"mov $60, %%rax\n" // exit のシステムコール番号 (60)
"mov $0, %%rdi\n" // 終了コード (0)
"syscall\n" // システムコールを呼び出す
:
:
: "%rax", "%rdi" // 破壊されるレジスタ
);
}
あまり考えたくないコードですね...
これはx86-64のLinuxでしか動作しません(注3)。すなわち、
- システムコールを直接呼び出しているため、Windowsなどには存在しない
writeのシステムコール番号を使用しています。 - CPUがx86-64アーキテクチャに対応していることも必要です。(e.g. AndroidスマホのAArch64やAArch32のCPUでは動きません)
- OSが64ビットモードで動作していることも必要で、32bitのLinux(x86)では動きません。
ですので、異なる仕様間で便利にI/Oを用いるプログラミングをするために、stdio.hが存在しているということです。
これらの異なる仕様をすべて吸収するために標準ライブラリを書いてくれた方々に感謝しなければいけませんね!
標準入出力関数とは
標準入力/標準出力とは、プログラムに明示せずとも標準の入力先/出力先になっているものです。
プログラムで実行された標準入力・標準出力は実行されたソフトウェアに引き継がるようになっています。
例:
- コマンドプロンプト(cmd.exe)で私たちがコンパイルした、"Hello, World!"を 標準出力 するプログラムを実行する。
- 実行中のcmd.exeに標準出力が委ねられ、標準出力の内容を表示しようとする。
- ディスプレイに表示!
なので、printf()を使って、標準出力をしてもその先は実行環境任せということですね!
stdio.h
C言語のstdio.hは、標準入出力ライブラリで、多くの便利な関数を提供しています。
以下に主な関数を説明します。
今は上の二つあたりを知っておくだけで大丈夫です。
また、難解な引数や返り値の定義も今は無視してください!
-
printf (const char* format, ...)
概要: 標準出力にフォーマットした文字列を出力します。
返り値:int
使用例:printf("Hello, %s!\n", "World"); -
scanf (const char* format, ...)
概要: 標準入力からフォーマットに従ってデータを読み込みます。
返り値:int
使用例:scanf("%d", &number); -
fgets (char* str, int count, FILE* stream)
概要: バッファサイズを指定して安全に文字列を読み込みます。
返り値:* char
使用例:fgets(buffer, sizeof(buffer), stdin); -
putchar (int ch) / getchar ()
概要: 単一の文字を出力または入力します。
返り値:int
使用例:putchar('A');/char c = getchar();
まとめ
- データ型とリテラル:
- C言語には、値の種類とそのメモリサイズを決定するデータ型があり、整数型、浮動小数点型、文字型などが存在します。プログラム中に直書きされた値(リテラル)は、型が自動的に設定されます。
- 変数の宣言と初期化:
- 変数を宣言して使用するには、データ型と変数名(識別子)を指定します。初期化しておくことで予期せぬエラーを防ぐことができます。
- 関数の宣言:
- C言語では、処理手順をまとめた関数を使用します。関数には引数と返り値があり、特定のデータ型を持つ値を返します。プログラムのエントリポイントであるmain関数を中心に構成されます。
- プリプロセッサ指令:
#includeを用いることで、外部の標準ライブラリやヘッダファイルから関数などを利用できます。stdio.hのような標準ライブラリには入出力処理に必要な関数が含まれています。
次のページでは、変数の宣言を具体的に学んでいきましょう!
課題 2
- C言語の演算子の種類について調べてください。
printf()やscanf()で使用される、C言語のフォーマット文字列について調べてください。- 以下のコードの未実装な部分を埋めるように、変数の内容を入れ替えて標準出力するプログラムを書いてください。(
ヒント: 変数の宣言が必要です)
#include <stdio.h>
int main() {
int a = 1;
int b = 5;
printf("a: %d, b: %d", a, b); // a: 1, b: 5 が表示される
// 未実装!
printf("a: %d, b: %d", a, b); // a: 5, b: 1 が表示されるはず
}
- 一つ上の課題を関数に切り出し、二つの
int変数を入れ替えて出力する関数にしてください。
#include <stdio.h>
int swap(int x, int y) {
// 未実装!
display(x, y); // 表示!
return 0;
}
int display(int x, int y) { // ただint型の二つの値を受け取り、表示する
printf("x: %d, y: %d", x, y);
}
int main() {
int x = 1;
int y = 5;
display(x, y);
swap(a, b);
}
注釈
注1
8bit = 1オクテット を 1バイト と表現しています。
C言語標準では、そもそも1バイトはオクテットに限らないですが、ここでは 1バイト としておきます。
注2
実際のC言語仕様には、main関数が必ず最初に実行されるわけではありません。
組み込みシステムなどのOSを使用しない環境、すなわちfreestandingな環境ではmain関数から始める必要はありません。
逆に、OSを使用するhostedな環境では、main関数がエントリポイントになります。
注3
面倒なコンパイラオプションを避け、みなさんがそのまま実行できるように、あえて hosted なC言語(main関数)を使用しているため、exit システムコールを呼ぶ必要はまったくありません。
変数の宣言
学べる事
- 変数宣言の意味と仕組み
- メモリと変数の関係
.rodataセクションの役割と位置- アドレス
- セグメンテーション違反
- スタック領域
- スタック
- 再帰関数
- スタックオーバーフロー
前頁で確認しましたが、変数の宣言は以下のようなものでした。
int main() {
// データ型 識別子;
int x;
}
ですが、なぜ変数の宣言がこの文法で、データ型と識別子が必要なのかを考えたことはありますか?
今までのような、プログラムに宣言した変数やリテラルは、そのプログラムの実行中に、
メモリに展開されます。
ある変数を宣言するためには、あるメモリ上の性質によって変数のサイズを知っておく必要があります。
上記のコードでは、そのデータ型のサイズ分を x という識別子でメモリ領域と結びつける必要があるのです。
それらを確かめるためには、実際に見てみるのが早いですね!
Hello, World! の中身
前頁のHello, World!プログラムとobjdumpを使います。
その中で、文字列リテラル"Hello, World!"がメモリのどこに配置されるのか調べてみましょう。
$ objdump -s hello
ここで、objdumpに-sと一緒に渡しているhelloは、hello.cをコンパイルした実行可能ファイル(バイナリ)でしたね!
objdumpを使用することによって、実行ファイルを解析し、情報を整理してくれます。
さあ、ひたすらにHello, World!の文字列を出力から探してみましょう!
Contents of section .rodata:
2000 01000200 48656c6c 6f2c2057 6f726c64 ....Hello, World
2010 210a00 !..
# ↑ 仮想アドレスが 0x2000 の場所に "Hello, World" が配置されている
見つかりました!
どうやら、.rodata という部分に入っているみたいです。
勘の良い人は分かったかもしれませんが、.rodataとは、 Read-Only Data のことです。
すなわち、.rodataに置かれるデータは、すべて読み取り専用ということです。
このプログラムにおいて、printfの引数の文字列は変更する必要がありませんし、できません。
.rodata
次は、hello.cに以下の内容を足してみましょう!
#include <stdio.h>
int main() {
printf("Hello, World!\n");
// 文字列リテラルは通常 .rodata に配置される
char *msg = "Goodbye, my past self.\n"; // 追加
return 0;
}
今は、謎のアスタリスク(*)は無視してください。(これは、あの ポインタ です...)
ただ、整数リテラルがintになるように、 文字列リテラル はアスタリスクのついた* charになるようなものだと思っていてください。
これでもう一度、以下を実行します。
$ clang -o hello hello.c
$ objdump -s -j .rodata hello
上記のコマンドの、-j .rodata で.rodataのみを表示しています。
そして、表示が変わりましたね!
Contents of section .rodata:
2000 01000200 48656c6c 6f2c2057 6f726c64 ....Hello, World
2010 210a0047 6f6f6462 79652c20 6d792070 !..Goodbye, my p
2020 61737420 73656c66 2e0a00 ast self...
先ほどの表示の後に、新しく追加された文字列リテラルが.rodataに追加されましたね。
char *strlit = "文字列リテラル" のようなコードは、すべて読み取り専用データに対する アドレス(メモリの特定の位置) を得ています。
さらに、そのアドレスはその文字列の先頭(アドレス)を指しています。
ですので、このように変数として宣言しても書き換え不可能ということです。
#include <stdio.h>
int main() {
char* str = "文字列"; // .rodata に置かれている文字列のアドレスを得る
str[0] = 'a'; // read-only なデータに書き込もうとしてみる
return 0;
}
上記を実行すると、以下のようなエラーが出ます。
$ clang -o ref_rodata ref_rodata.c
$ ./ref_rodata
Segmentation fault (core dumped)
Segmentation fault(セグメンテーション違反) とは、アクセス権のないメモリにアクセスしようとしたことを意味します。
このプログラムで、読み込み専用なデータに書き込むことはできないことが実証できました!
なお、.dataセクションには書き換え可能な変数(グローバル変数)が置かれます。
ですが、* char(char* strlit)が読み取り専用データに対する位置を表す型ということではありません。
詳しくは、ポインタのページで解説します。
.rodata はどこに?
さて、次はその.rodataがメモリのどこに展開されるかを見てみましょう。
$ objdump -h hello
上記のコマンドを実行し、.rodataと書かれた部分を探してみてください。
Idx Name Size VMA LMA File off Algn
...
16 .rodata 0000002b 0000000000002000 0000000000002000 00002000 2**2
...
ありましたね!
VMA (Virtual Memory Address) の下に書かれている0000000000002000は、.rodata が
展開したいアドレス(仮想アドレス)を表します。
VMAは、OSが実際のメモリに対して、プログラム側で扱いやすいように(また安全のために)提供する仮想的なメモリのアドレスのことですが、詳しくは扱いません。
(仮想アドレス空間(英語) <- はこのページで話す内容と少し被っています)
また、厳密には実行されたときにロードされるアドレスとVMAが一致するとは限りません。
多くの場合、 ASLR, アドレス空間配置のランダム化の影響などを受けます
(ASLRを無効化すると、0x2000に.rodataが展開されます)
メモリ
メモリとして、以下のようなものを考えてみます。
.rodataはアドレスの0x0000000000002000に展開されましたね。
(注: 0xに続く数字は、16進数を表します)
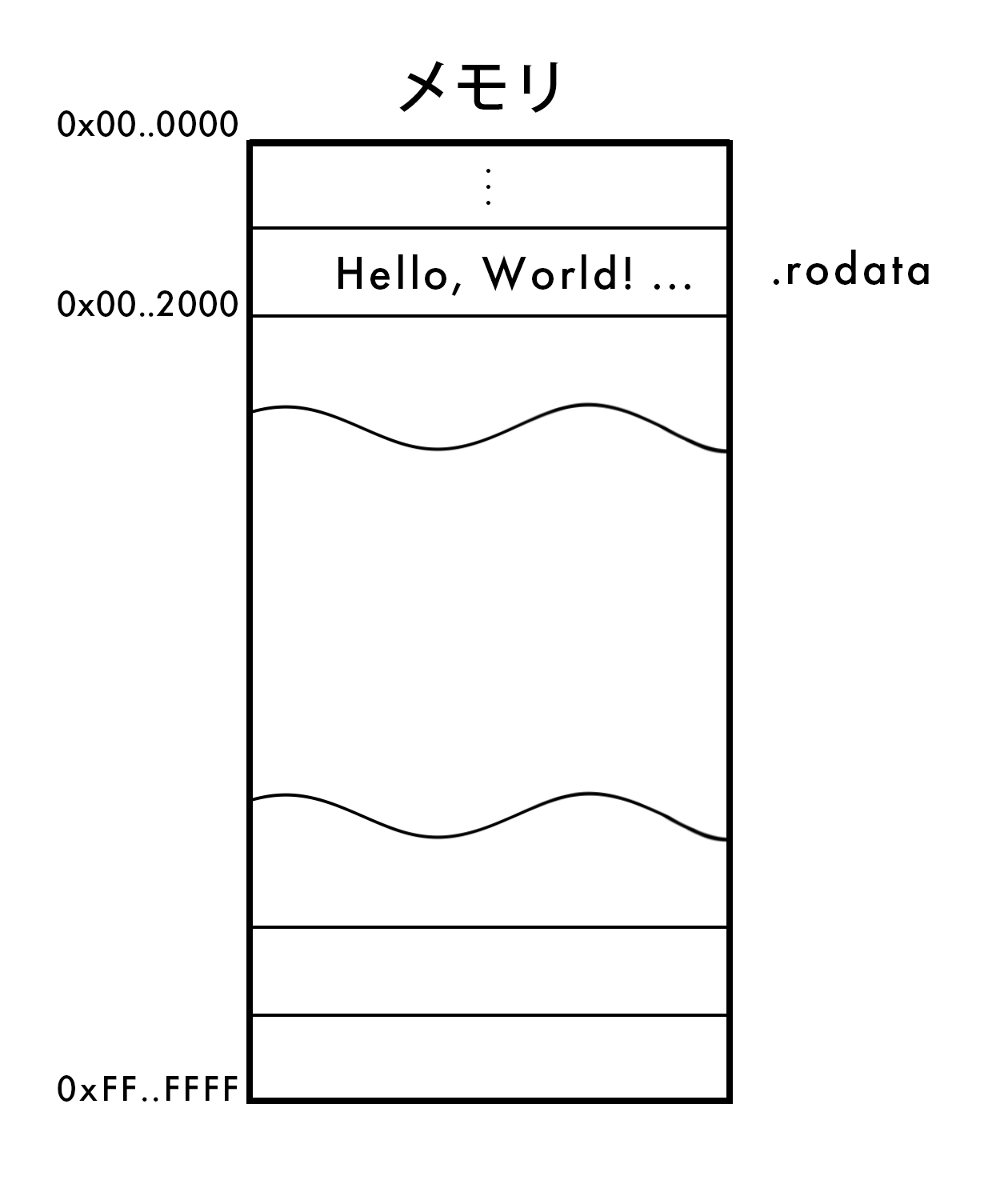
今までの情報から、以下のことが分かります。
- Hello, World!プログラムがコンパイルされたとき、
"Hello, World!"は読み取り専用の.rodataに配置される - このプログラムにおいて、文字列が書かれている
.rodataは、0x0000000000002000に展開される
実は、Hello, World!での文字列リテラルは、既に実行されたときに展開される場所が決まっているのです。
そして、この図で見るなら、かなり.rodataは上の方ですね!
また、これらはmain()などが実行される前に、メモリに展開されます。
今まで話した.rodataは、静的領域 と呼ばれるものの一部です。
これは、私たちの具体的な認識に対して抽象的な言葉ですが、メモリの一部として話されることがあります!
あれ? 私たちが宣言してきた変数はメモリ上のどこにあるのでしょうか?
スタック領域
今まで、コンパイルされた実行可能バイナリを解析して展開されるアドレスを見てきました。
今度は、プログラムで関数内に宣言された変数のアドレスを見てみましょう。
#include <stdio.h>
int main() {
int x = 0;
// %p で、アドレスを表示することができる
printf("%p\n", &x);
}
ここで、&xはその変数xが格納されているアドレスを得ることができます。
addr.c としてコンパイルし、実行してみます。
$ clang -o addr addr.c
$ ./addr
0x7ffd494ffecc
0x7ffd494ffecc という値が得られました。
これは、あなたの環境で似たような値が得られても、全く同じではないと思います。(先ほど注釈した、ASLRの影響です。何回か実行しても、値が変わると思います。)
さて、これらは今までのアドレスと異なって、かなり値が大きく見えますね。
実は、関数の中で宣言された変数は、 スタック領域 と呼ばれる、メモリの下の方に格納されます。
図に表してみましょう。
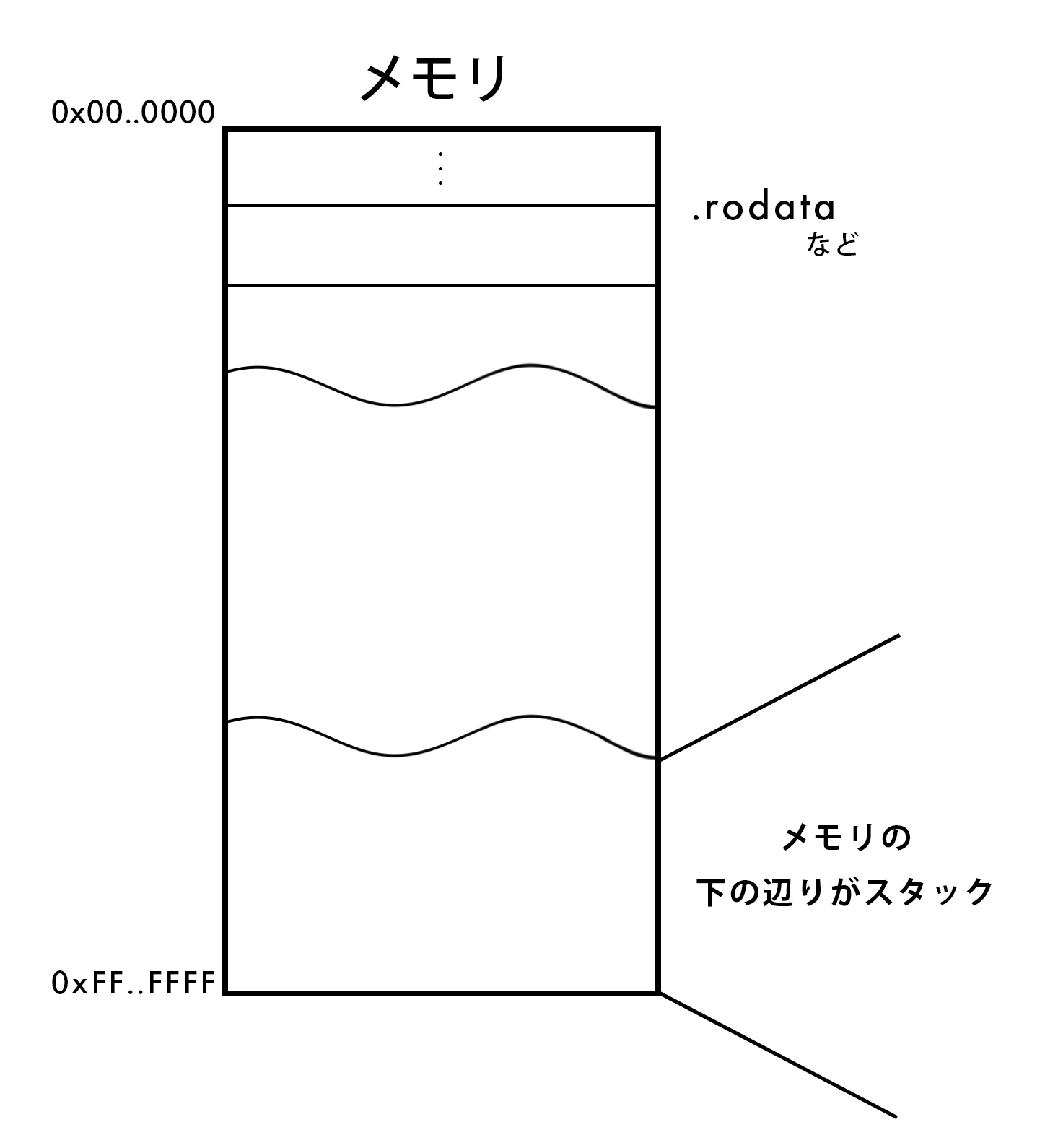
スタック領域は、多くの場合メモリアドレスの大きい方から、小さい方へ使われます。
より分かりやすくしてみましょう。
先ほどのaddr.cを以下のように書き換えてください。
#include <stdio.h>
int main() {
int x = 0; // 先にxを宣言
int y = 1; // 次にyを宣言
// それぞれのアドレスを表示
printf("x: %p\n", &x);
printf("y: %p\n", &y);
}
上記を実行します。
$ clang -o addr addr.c
$ ./addr
x: 0x7fff58c6dc8c
y: 0x7fff58c6dc88
xとyのアドレスを比べて、値の差をとってみると0x...c8c(cは10進数で12) - 0x...c88 = 4 でintのサイズと一致することも分かりますね!
また、変数yはxの後に宣言されたはずです。
ですが、xに比べて4バイト前のアドレスにあることが分かりますね。
これが、 スタック と呼ばれる所以です! (後でもっと詳しく説明します)
このプログラムを図に表しましょう。
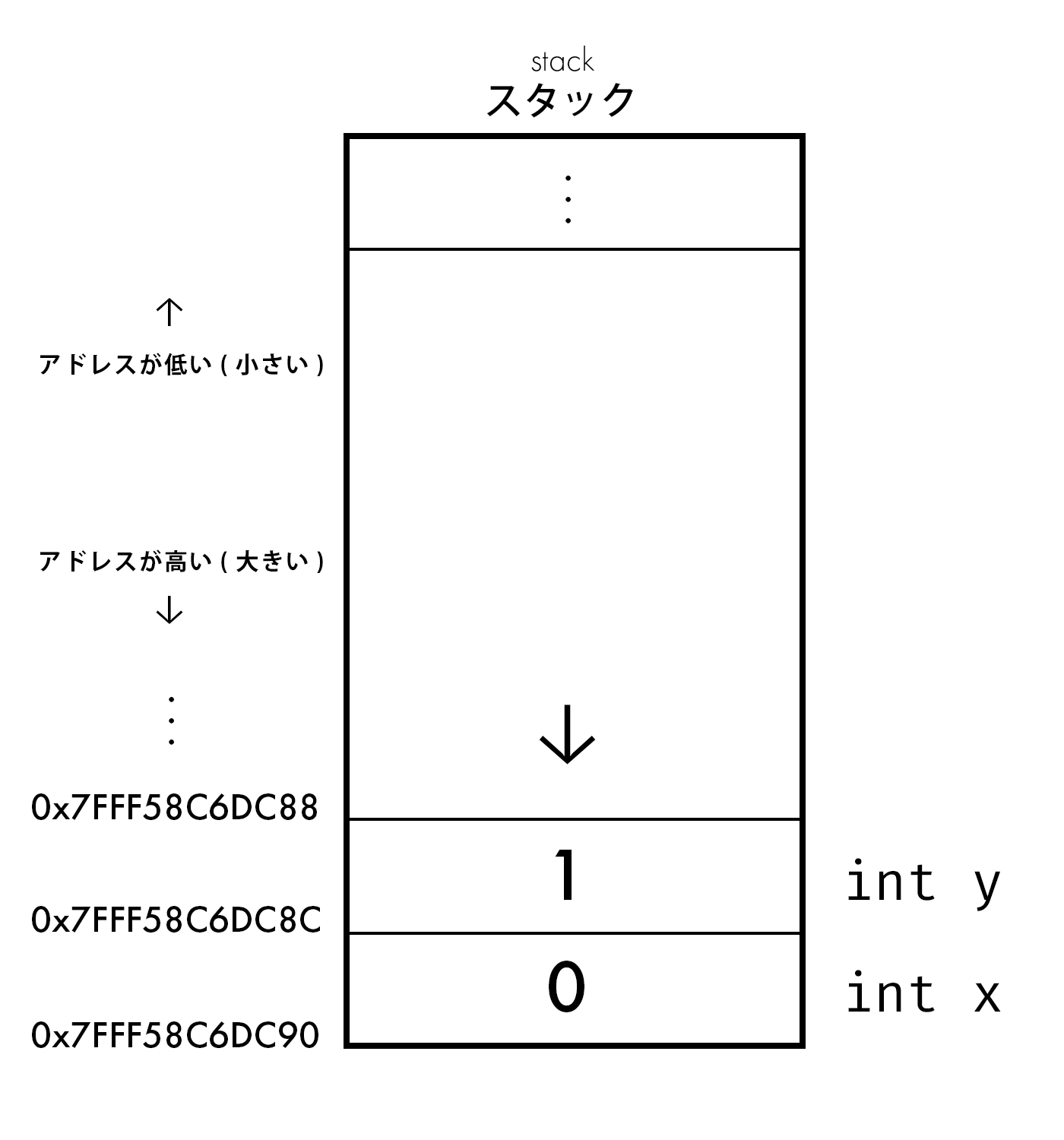
ここまでの内容を纏めます。
- 関数内に宣言された変数は、スタック領域に配置されます
- スタック領域の変数は、アドレスの大きい方から小さい方へと置かれていきます
スタック
スタック領域は、何がスタックなのでしょうか?
スタック領域は、変数を宣言し値を順番に入れていくと、また入れた順番とは逆の方向に値を取り除いていきます。
これを、 Last In, First Out (LIFO) といいます。
日本語で言うなら 「最後に入れたものが最初に出てくる」 というところでしょうか。
また、その LIFO の性質をもつのがスタックということです。
積み上げられている皿を想像して下さい。
皿を追加するときには、積みあがった皿の一番上に置き、皿が必要になったら、一番上から取り除きます。
また、積み上げられている真ん中の皿を取り去ったり、皿の一番下に追加することは出来ません。
スタック領域において、先ほどのプログラムでのxとyは積み上げられていますが、勝手にアドレスをずらしてその間に変数(値)が追加されることはないということです。
それにデータを追加することを、スタックにpushするといい、データを取り除くことは、スタックからpopするといいます。
今は気にしなくて大丈夫ですが、変数に結びつけられた値が積み上げられたあるプログラムのスタック領域があるとします。
それにおいて、すべてアドレスが連続的に変数と結びつけられた値が入っているというわけではありません。
これは、データ構造アライメント, メモリアライメント などと関係しています。
要するに、スタックだからといって、すべて変数と結びつけられた値が隙間なく詰め込まれているとは限らないということです!
Rustはどうして...?
Rustという言語は、変数の宣言に型が必ず必要ではありません。
う~ん、それはどうしてでしょうか?
以下のC言語のコードをRustで真似してみましょうか。
C言語:
// 省略
int x = 0;
//省略
Rust:
fn main() { // let 識別子 代入演算子 式; let x = 0; }
let は、データ型ではなく、変数の宣言のためのキーワードです。
今度は、C言語のこのコードを真似してみましょう。
C言語:
int x;
Rust:
fn main() { let x; // ...これでいいの? }
ご想像のとおり、このRustコードは以下のコンパイルエラーが出ます。
error[E0282]: type annotations needed
--> src/main.rs:2:5
|
2 | let x; // ...これでいいの?
| ^
|
エラー文には、"型注釈が必要です" と指摘されています。
ですので、以下のいずれかの方法で変数を宣言できます。
Rust:
#fn main() { let x: i32; // i32 であると指定 // 初期化しようが、変数xは i32 型(32bit整数)の変数 let x; // 0 が代入されているので、xは自動的に i32 と判断される x = 0; #}
Rustは、型推論という仕組みを利用して、変数に適切な型を自動的に割り当てます。たとえば、以下のコードを見てください。
fn main() { let x = 42; // 型推論によって x は i32 と判定される let y: f64 = 3.14; // 明示的に型を指定することもできる }
型が判明することによって、どんな値かが分かれば、そのサイズも分かりますね。
このことから導き出される結論は以下の通りです。
スタックに変数を宣言するためには、どんな言語であれ サイズ を知る必要があります。
C言語の以下のコードにおいて、なぜ変数の宣言ができるかというと、サイズが分かるからです。
int x;
intは基本的に4バイトでしたね。
なので、スタック領域に4バイト分を使うということを宣言しています。
(変数の宣言をした時点で、基本的にはスタックに置かれるアドレスが決定されます。決して、アドレスは代入時に決定されません)
Rustでも、このようにすれば サイズ を知ることができます。
fn main() { let x: i32; // 32bit の分スタックをxが使うことを宣言する }
変数の宣言がおおよそ何をしているかが分かりましたか?
なぜサイズが判明しないといけないか
最初に、C言語において、宣言する変数はサイズが判明していないといけないと言いました。
スタック領域に変数を積み上げるとき、サイズが分からないとどうしようもありません。
例えば、スタック領域に配置される、あえてサイズが不定の変数xを宣言できるとしてみましょう。
加えて、int型の変数yを宣言するとき、一つ下の変数xのサイズが分からないのに、どこに積み上げれば良いのでしょうか?
逆にその上の4バイト上のアドレスをyがとるものと仮定しても、xが4バイトを超えるデータを書き込んだ場合、yの領域を突き抜けてしまいますね!
そういった意味で、スタックにどのような変数や値が積まれるかは、コンパイル時にある程度判明していなければならないということです。
ここで、賢い人なら疑問に思ったかもしれません。
もし、プログラム内でどのような変数がスタック領域に配置されるかが判明するなら、コンパイラは予言的で、すべてのスタック領域の変数の動きも既に決まっているのでしょうか?
また、スタックのすべての動きを追うことができるなら、再帰的に自身の関数を呼ぶようなものはどのようにコンパイルされるのでしょうか?
実は、コンパイル時にサイズが決まっている変数は、関数(ルーチン)毎にサイズが計算されます。
関数内で宣言される変数や、関数の呼び出し元はどこか、引数は何かなど、様々な情報を纏めて、関数ごとにサイズが計算されています。
この様々な情報の集合を、 スタックフレーム といいます。
再帰関数
先ほどの"再帰的に自身の関数を呼ぶようなもの"の例をみてみましょうか。
#include <stdio.h>
int func(int x) {
printf("%d\n", x);
int y = 1;
return func(x + y);
}
int main() {
func(0);
return 0;
}
このコードにおいて、func() は、再帰的であるといえます。
func()は、main()から最初に受け取った0に、yの1を足していき、また自身を呼び出すために渡される値xは増加していきますね。
このコードをrec.cとして、実行してみます。
$ clang -o rec rec.c
$ ./rec
0
1
2
3
...
261877
261878
261879
Segmentation fault (core dumped)
Segmentation fault を起こしてしまいました。
これは不正なメモリアクセスに対して発生するものでしたね。
また、コンパイラは、プログラムのすべての流れを追うように変数のサイズを計算するのではなく、関数ごとに行われているといいました。
func()はint型の引数xと変数yを宣言しており、main()に呼ばれた、またはfunc()自身から呼ばれたなどの情報の集合が、スタックに配置されることがコンパイル時に判明しています。
ですので、予言的にスタックにどんな値が積まれるかを知ることはしていませんが、関数ごとに使用するスタックのサイズや、どのように積むかはコンパイル時に分かっているということです。
ここでは、func()のスタックフレームが、コンパイル時に判明しています。
関数呼び出しが無限に行われることによって、スタックに情報が積み上げられ続け、スタックの容量の限界を迎え、別のメモリ領域を突き抜けようとしたために、Segmentation fault が発生したということです。
これを、 スタックオーバーフロー (Stack overflow) といいます。
(また、実行するたびに表示されるxの値が変わると思いますが、それもまたASLRの影響です... 簡単に言うと、スタックの開始アドレスがランダムに変わるためです)
では、サイズがコンパイル時に判明している変数やデータしか、プログラムで扱うことができないのでしょうか?
ここで、メモリ上のアドレスを0x000..000から0xFFF..FFFのどれかを保持するために、サイズが判明している変数pを考えてみましょう。
また、値を積み上げず、レストランのように空いている場所に値を書き込んでいく別のメモリ領域を考えてみましょう。
これを、ヒープ領域 としてみます。
pは、サイズが判明するために、スタックに配置されます。
pが保持するアドレスをヒープ領域を指すものとすることによって、この時点でコンパイル時にpのサイズは判明するものの、そのアドレスが指す値のサイズは実行前に分からない、ヒープ領域上でサイズ変更が可能なデータを扱えるようになりました。
そうです。私があえて話していなかった、メモリ図の真ん中辺りの領域は、ヒープ領域だったのです。
詳しくは、ポインタを解説した後にしましょう。
ですがポインタは、アドレスを保持し、それが.rodataやスタックやヒープ領域を指すことができるというのです。
(ここで、あえてこの変数pをポインタであると言わなかったのは、ポインタとは単純なアドレスを保持するものではないからです。
混乱させるようですが、中級者の方はStrict Aliasing Rulesなどを調べると、自身での新たなポインタの解釈が生まれてくると思います。
ここで、それらを加味した、現時点での私の解釈を言うのであれば、『ポインタとは、ある記憶域から生成されたオブジェクトを一意に決定できる値とそのオフセット』です。ですが、分からない人は全く気にしないで下さい。)
次は、今まであえて使っていなかった、制御構造(e.g. if, while)や、文と式について話します。
文と式
学べる事
- 式とは
- 文とは
ここからは、前回とはまったく異なるアプローチで、C言語を説明してみます。
What is 式
基本事項のページ で、初期化を伴う変数の宣言は以下のようなコードでした。
int main() {
// データ型 識別子 代入演算子 式;
int x = 0;
}
ここで、 式 とはC言語の構文がとる一つの要素です。
この説明を、本ページを通して解説していきますが、最初のうちは分からないのが当たり前です。
まず、C言語において、以下はすべて式です。
01.1~0(~は単項演算子で、ビット反転)1 + 1"Hello"(また詳しく説明しますが、Helloに対する先頭アドレスを保持する値として評価されます)1 < 2(<は比較演算子。この式はtrueとして評価されます)(1 + 2) - 3 * 4 / 5 % 6(整数リテラルは、intでしたね。もちろんこの式の結果はintになります)
なにか思うところがあるかもしれませんが、C言語及び多くのプログラミング言語において、ただの整数リテラル0も、式 なのです。
あえて今のうちに説明するなら、C言語において 式 は演算子を含む必要はまったくないのです。
What is 文
int x = 1 + 1;
この初期化を伴う変数の宣言において、1 + 1は式ですね。
そして、これは 代入 文 です。
代入文は次のような構文(文法)をとるものでしたね。
データ型 識別子 代入演算子(=) 式 ;
例:
// データ型 識別子 代入演算子(=) 式 ;
int x = 0;
そうです。式は、代入文の構成要素となっています。
関数がもつ文
#include <stdio.h>
int main() {
printf("Hello, ");
printf("World");
printf("!\n");
int x = 1 + 1;
123; // 式; で文となる
return 0;
}
この例では、main関数は6つの文をもっています。
関数が)の後にとりうるブロック({})の中には、任意の数の文を書くことができます。
他の文の例をみてみましょう。
return文
return文の例をみてみましょう。
int main() {
return 0;
}
これは何もないプログラムですが、0は式です。
このことから、return文の構文は次のようなものであると考えることができます。
return 式;
他の例もみてみましょう。
int one_add_two() {
return 1 + 2;
}
この関数で、return文はreturnキーワードの後に1 + 2の式をとっています。
1と2はintの整数リテラルで、+は、二つの(二項の)被演算子(オペランド)をとる、加算を行う演算子(オペレータ)です。
また、変数は式の一部になり得ます。
以下の例で説明してみます。
int sum(int x, int y) {
return x + y;
}
return文がとる式に、x + y が書かれていますが、もちろん文法上のエラーはないですね。
変数の宣言でも同様です。
int main() {
int x = 1;
int y = 2;
int z = x + y;
// int z = 1 + 2; と同じ
}
変数の宣言において、代入演算子の後は式で、ここでは1, 2, x + y がそうですね!
このように、変数は式の一部になることが分かりましたか?
関数呼び出しは式?
また、値を返す関数は、式になります。
int sum(int x, int y) {
return x + y;
}
int main() {
int a = sum(1, 2) + 3 + sum(4, 5);
return 0;
}
ここで、sum()はintを返すので、有効な式で、aは15になりますね。
このように、ある例外を除いて関数呼び出しは式になります。
例外とは、返り値がvoidの式です。
void
void とは主に、「何もない」または「型がない」という概念を表す型で、キーワードです。
実際のところ、複数の役割をもつために、一つの言葉で纏めることは難しいです。
ですが、今までのとおり、voidを識別子に使うことは出来ません。
以下の例は、そのvoidの役割の一つである、関数の返り値の型がvoidになっている例をみてみましょう。
#include <stdio.h>
void f() {
printf("Hello\n");
// 値を返さないため、return 文には式がない
return;
}
int main() {
f();
return 0;
}
この例で、f()の返り値の型は、voidになっていることが分かります。
そして、return文の定義は、
return 式;
のようなものではなかったですか?
この例では、式が書かれていませんね。
関数の返り値の型に void を指定すると、その関数は値を返さないことを示します。
つまり、関数の返り値として void を使うことで、呼び出し側は戻り値を期待しなくてよいことが分かります。
式文
先ほども少し例に示しましたが、以下はすべて 式; という構文をとる式文です。(注: あまり一般的でない名前)
123;
1+1;
printf("Hello!"); // 実はprintf()の返り値は int: 標準出力された文字列のバイト数
x;
if 文
続いて、今まで避けてきたif文を以下に示します。
見たことがある人ならば、ある程度構文を予想できるのではないでしょうか。
if (式) {}
また、ブロックのすぐ後ろに、任意の数のelse if (式) {}と、任意のelse {}をとります。
if (式) {
} else if (式) {
} else if (式) {
} else {
}
ここで、最初のif文がもつ式が最終的に1に評価された場合、if文がとりうるブロック内が実行されます。
また、それが0と評価された場合、一つ下のelse ifが評価され、さらにその式が0であった場合、elseが実行されるか、elseが存在しない場合はif文が実行されないことになります。
0/1と評価されるとは、どういうことでしょうか?
C言語における論理演算は、等価演算( == )や非等価演算( != )、論理積( && )、論理和( || )などが挙げられます。
それらの論理演算が真のときは1、偽のときは0と評価(計算)されます。
(実際には、0意外のすべての値が真とされます)
逆に、先ほども言いましたが、ただの整数リテラルも式でした。
if (0 /* 偽 */) {
do_something();
}
このようなコードを書いても、明らかに構文上正しいですし、絶対に実行されないif文が完成することになります!
文と式
いきなりですが、問題です。
以下は、構文上問題のあるコードでしょうか?
int x = if (1 != 2) {
return 42;
} else {
return 0;
};
よく考えてみましょう。
変数の宣言の構文は、以下のようなものでした。
型 識別子 = 式;
さて、もしこのコードが正しいとするなら、if (1 != 2) {...}の;までの部分は式になります。
ですが、if文は if 文 でしたね?
そうです。
C言語では、if文は文であって式でないので、このコードは構文エラーとなります。
if文のブロックの中は、任意の数の文を期待する(もつ)ので、return 文 が来ていることについては正しいですが、これは関数を終了させる処理で、if文とは関係がありません。
また、"C言語では" と言いました。
これは、また逆に if式 が存在する言語があるということです。
それは前に登場したRustです。
Rustでは、以下のように書くことができます。(▶マークで実行ができるかもしれません)
Rust:
fn main() { let x = if 1 != 2 { 42 } else { 0 }; println!("{x}"); // 42 }
このように、式と文の区別がついたでしょうか?
if文がとりうる括弧の中は式であると具体化しましたが、多くは論理式や条件(condition)と呼ばれます。
課題
検索やこのページなどを読んで、他の制御構文を、ここで覚えた文と式の違いに着目して理解してください。